Say "Yes" to JavaScript →
Armin Ronacher, on Firefox’s removal of the option to disable Javascript:
My immediate response to change of removing the switch was: “Thank god, that should have happened ages ago”.
…
You don’t get extra privacy by disabling JavaScript. I can fully track you even without JavaScript. At the same time I can enhance your browser experience through better written JavaScript code that allows me to do things with your browser that plain HTML does not allow.
If you’re really paranoid about your privacy, use Firefox, enable the Do Not Track flag in your options, enable click to play for plugins like Flash or Silverlight, and install the Ghostery and Adblock extensions. Anything else is just going to break the web at your own expense.
What Microsoft Should Have Done →
Soren Johnson, lead designer of Civilization 4:
The answer is to make digital games so attractive that players will abandon physical discs on their own. (One might call this the Steam strategy.) Microsoft could have avoided this whole fiasco by maintaining the old disc-based ecosystem while softly undermining it with three moves that create an alternate digital future.
Combined, these three changes would destroy the traditional retail market. The $40 price would make digital games cheaper at release; the ongoing heavy sales would undercut the used games market; and persistence would make digital games easier to maintain across multiple devices. Microsoft needs to make buying games digitally a better deal for the consumer than buying them physically.
I was extremely disappointed to hear Microsoft cave in to rabid demands to maintain the status quo. I was really looking forward to their plans for combined physical and digital ownership, where I could get all the benefits of buying physical copies, including special and collectors’ editions of my favorite titles, while simultaneously retaining all the benefits of a digital copy, like the ability to forego disc-swapping.
How long will we have to wait for consoles to catch up with Steam?
Push Push Push
One of my favorite projects that I’ve created has to be ZNC Push, a plugin for ZNC that generates push notifications for IRC highlights and private messages. It supports a wide array of push services for all of the major mobile platforms, and gives the user deep flexibility in choosing how and when to trigger these notifications.
However, I have very little insight into usage statistics for the plugin. Pushover is the only service that gives me gross usage data, but considering ZNC Push supports six other networks as well as custom push URLs, this only represents an unknown portion of the total usage. But I will continue to draw baseless conclusions from it regardless! Do note that I can’t see anything more than raw volume of notifications; I do not have access to who is sending/receiving these, nor the contents of those messages.
So without further ado, some pretty graphs straight from the Pushover dashboard:
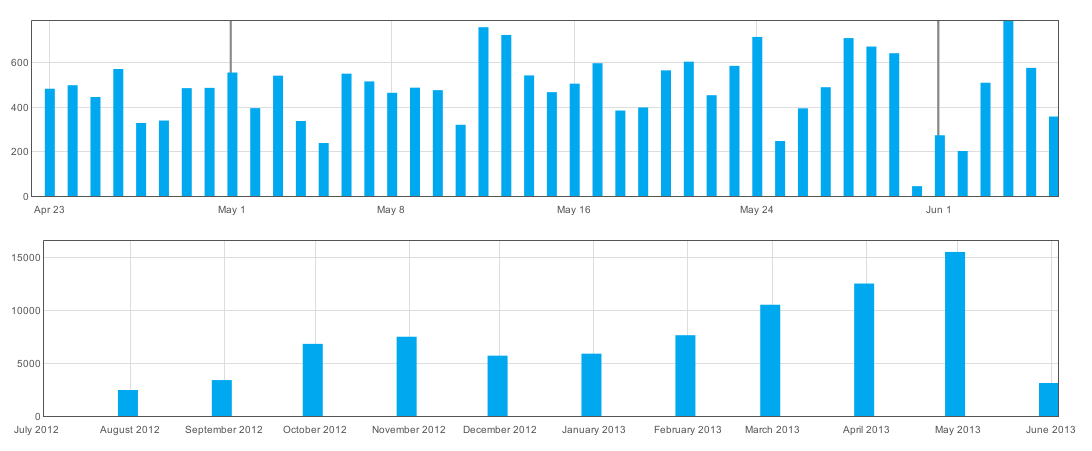
ZNC Push reached a milestone of sending 15,000 push notifications in May through the Pushover service!
Push volume has been growing steadily since Pushover support was added, with a small dip in December and January that is likely attributeable to the holidays for most users. May marked the second occasion that ZNC Push has exceeded the volume “cap”, and Pushover has again graciously increased that in support of this open source project. At this sort of grawth rate, I would expect the next volume cap (25,000/mo) will be reached by October at the latest. I’m excited to see such growth for a small side project with such a niche use case.
Sometimes, it’s amazing to stop and realize just how far this project has come. What started in January of 2011 as a basic module for the Notifo push service, has blossomed into a mature system supporting multiple push services and far more customization options than I had ever envisioned from the beginning. Knowing that it’s being used by so many people, and helping them stay more connected with their online communities, makes me a very happy engineer.
Many thanks to Pushover for granting such a large volume of free notifications to ZNC Push. If you’re not already using them for your push service of choice, I highly recommend them. They have apps for both Android and iPhone, and they continue to improve them and add new features over time.
And as always, my eternal appreciation to everyone who has contributed time and energy to helping me improve the module over the past two and a half years! The project wouldn’t be where it is today without your support.
Favorite Android Apps of 2012
Eighteen months ago, I wrote an article about my Favorite Android Apps, but a lot has changed with Android and its app ecosystem since then. Developers have started putting more focus on design and usability when creating apps, and of course newer apps have come along that I have come to rely upon. I myself have upgraded to newer devices, with a Nexus 7 replacing my Galaxy Tab 10.1, and a Galaxy Nexus from work has sadly replaced my beloved but aging Nexus S. So what follows are some of my favorite new apps from 2012, and some follow-up on what my previous favorite apps look like in modern attire. All screenshots are taken from devices running Android 4.2.1 (CM 10.1 nightlies).
Why Ralf Prefers Android →
Along a similar vein as my previous post on Why I Prefer Android, Ralf Rottmann, a self-described “Apple fanboy”, has described why I prefer Android better than I could in my own words:
The latest version of Android outshines the latest version of iOS in almost every single aspect. I find it to be better in terms of the performance, smoothness of the rendering engine, cross-app and OS level integration, innovation across the board, look & feel customizability and variety of the available apps.
On the topic of app and system integration:
Another great example: Sharing stuff on social networks. On iOS, I have to rely on the developers again. Flipboard, as one of the better examples, gives me the ability to directly share with Google+, Twitter and Facebook. On my Nexus 4, I have 20+ options. That is, because every app I install can register as a sharing provider. It’s a core feature of the Android operating system.
…
All of this is entirely impossible on iOS today. I’ve stopped counting how often I felt annoyed because I clicked a link to a location in Mobile Safari and would have loved the Google Maps app to launch. Instead, Apple’s own Maps app is hardcoded into the system. And there’s no way for me to change it.
Regarding possibilities for app developers:
On iOS, many things I always wished to see being developed, simply cannot be done because of the strict sandbox Apple enforces around apps.
…
I also have apps [on Android] that give me great insight into the use of mobile data across the device and all apps. Or the battery consumption. Or which apps talk home and how frequently.
None of it is available for iOS. And possibly won’t be at any time in the near future.
And summing up the way I’ve felt for a long time when using iOS devices:
… whenever I grab my iPhone for testing purposes, iOS feels pretty old, outdated and less user friendly. For me, there currently is no way of going back. Once you get used to all of these capabilities, it’s hard to live without them.
There are many things Apple got right with iOS, like making a consistent user experience, and encouraging users to spend money in the market for quality apps. But when they place so many restrictions and limitations on how you can use your phone, and what your software is allowed to do on your own device, I gladly give up those things that make iOS so great for the freedom to run apps that can do what I want — and expect — from a modern computing device.
Powered by Nib
For the last couple years, this site has been managed and updated using the open source static site generator called Poole. It is an excellent and simple system, comprised of two Python files — the Poole source code and a site-specific macros.py — a simple page template, input documents and static content. This is more than enough for a small static website, but more complicated sites, like blogs, require quite a few macros in order to generate things like archives, tag pages, or even RSS feeds. Over the 18 months that I worked with Poole, my macro file had gotten a bit disorganization, and the limitation of working from only a single template file was starting to strain on what I could do with it.
Now keep in mind, I still like many of the features that drew me to Poole in the
first place, such as the use of a document-centric build process, with YAML
headers for defining page metadata rather than an inline, proprietary format
used by projects like Jekyll. I also enjoy the simplicity of the content
representations, but the lack of an extensible content pipeline is my biggest
complaint. Supporting formats other than Markdown requires adding yet another
hook to the macro file; generating archives and tag pages required hacking in a
multi-phase build using os.exec(); and inlining another page’s content
post-render was just not possible, resulting in Markdown named-link collisions
when rendering multiple posts to a single page.
I wanted something new. So, for the past few months, I’ve been working on Nib.
The resulting design is based heavily on the concepts of Poole, but built around a primary goal of producing a proper content pipeline that is simultaneously aware of the differentiation between resources and documents, and defines multiple stages where plugins can hook into the process and alter or generate page contents at build time. Indeed, most of the actual functionality of Nib is contained within a handful of plugins, while the main module merely defines a framework for the content pipeline.
In effect, adding support for more content or resource formats should be as simple as adding a new plugin attached to the appropriate file extensions. Advanced content manipulation, generating “virtual pages”, and aggregating pages or documents into multiple locations are all possible as well.
The Markdown plugin is 14 lines of code; the LessCSS plugin is 13; even the blog plugin — which generates the archive pages, tag listings, and Atom feed — takes only 86 lines to do a better job than the old Poole macros that required double the effort.
Today, I’ve thrown the switch. While it looks nearly identical to the old site generated by Poole, the page you are now reading has officially been generated by Nib. The news feed sees the biggest makeover, having changed formats from RSS to Atom, and now offers full content posts. Link-style posts, a format that I’ve been wanting to experiment with, are also a new option. Both features would have required more effort on Poole than I was interested in expending, but the new architecture has allowed me to indulge myself.
Nib is still in an extremely early, and unstable, phase though. It works for the needs of my site, and does come with some basic documentation and a sample site to start from, but it’s far from complete. Near term goals include adding support for an intelligent menu, as well as support for more content and resource formats, like reStructuredText or SASS. Contributions are always welcome though, even at this early stage. Nib is liberally licensed, and I would love to hear feedback from anyone trying to use it. Hopefully it will be useful for someone other than myself.
Why I Prefer Android
What do you prefer about Android?
I prefer Android because it allows apps to do more things for the user, and allows them to better integrate with the system as a whole.
I can replace the on screen keyboard with one that has a full five-row keyboard for times when I SSH into a machine. On a similar vein, when I SSH into a machine, I can actually leave the SSH session running in the background while I switch to another app, without fearing that the OS is about to kill my SSH app while I’m looking something up or responding to a text message. I can also leave my IRC client running in the background without it constantly needing to reconnect when I switch back to it.
Intents in Android, especially in combination with the global Share mechanism, allow any app to receive arbitrary data from any other app, meaning apps don’t need to know about specific apps or services in order to integrate with them. Clicking on a URL allows you to choose which browser (or set a default) to open the link in, allowing you to use alternate browsers (or alternate email clients, SMS apps, dialers, etc); tapping Share in the browser allows you to send the current URL to any application that can receive a URL, making apps like Instapaper, Pinboard, and 3rd party Twitter clients have the same capabilities as first party applications.
Sideloading apps means I’m not limited to installing programs from the Android Market/Play Store, and can do things like buy apps directly from the Humble Indie Bundle and install them on my own.
Proper background service support, and allowing apps to affect things outside their sandbox, lets me run programs like Locale that can monitor the phone’s status, location, etc, and modify the phone’s settings automatically based on a set of conditions that I’ve pre-arranged. My phone automatically silences itself at night time and while I’m physically at work, turns on my Wifi when I’m at home or work while defaulting it off when I’m out and about, and more.
That’s just some of the reasons I like Android better than iOS.
Hack
The past two months have been intense. At the beginning of May, I was let go from BioWare and Electronic Arts in a round of budget cuts for my studio. Since then, I’ve played far too many video games (and beaten multiple titles), slogged through innumerable interviews, redesigned my website from the ground up, and celebrated my seventh wedding anniversary in some of the best summer weather I’ve ever experienced.
Oh, and I got a job at Facebook.
On May 3rd, BioWare informed me that my position in the studio was being eliminated. My terrible luck had struck again. But this time was different; within a few days, a recruiter from Facebook found this website and my open source work, reached out to me, and encouraged me to apply for an engineering role. Four weeks later, after phone screens and an on-site interview, I was offered a position as a Production Engineer. My luck had not only reversed, it had gone off the scale in the opposite direction.
Alongside Facebook, all my other leads paled in comparison. I wanted to stay in gaming, but here was the opportunity of a lifetime, to join one of the biggest and best engineering companies in the world, and the chance to learn from some of the brightest minds in the industry. The position is similar to the role I had at BioWare: writing and maintaining software to manage and automate the vast array of infrastructure that supports the front-end applications and engineers. It was an offer I couldn’t refuse.
Monday was my orientation, and I was immediately impressed by the level of passion, vision and dedication from the entire team. Boz discussed the culture of “hack”, and told a story about building a loft in a war room when it couldn’t fit everyone in just two dimensions. Chris Cox gave an inspiring talk about where Facebook is heading, and I got a surreal sense of wonder when he mentioned our long term goals or the level of impact we have on global society and the way people communicate. It feels amazing to be part of a company that truly wants to change the world and improve the lives of hundreds of millions of people.
Even the training process embodies those same ideals. The first few weeks, every engineer goes through “bootcamp”, attending learning and development sessions, sitting among other bootcamp engineers, and working with veteran teammates on real tasks to get familiar with the infrastructure, tools and codebase. Everyone is given the chance to progress at their own pace, with as much or as little help as needed. I’ve already learned so much in a few days, and I’ve also had the chance to share my own knowledge and experience with my fellow newcomers. And yet there’s still so much left to cover.
Wednesday was my first day at a desk. Taped to the monitor was a sheet of paper printed with bold, red lettering.
What would you do if you weren’t afraid?
I don’t have an answer for that yet, but I will soon.
Me, PHP and MantisBT
I’ve been spending time migrating my server from Ubuntu 10.04 to Arch Linux, and in the process I thought very deeply about every PHP application installed on the old server. Five out of the six PHP apps were only there to support the one that really stood on its own: MantisBT, my long-standing bug tracker of choice.
Now, I’ve been a core developer, and de facto release manager, for the project for many years — since I was still in university and getting paid by my then-employer to contribute features and plugins that they wanted to use for their engineering team. Those plugins, like Source Integration, wouldn’t be free without me fighting to license and release them for the community. And I wouldn’t be where I am today without the experience and help I received in turn from the very same community.
I know I haven’t been as involved in the project these days as I would like to be; there is an endless list of features and improvements to make to both the core system and the array of plugins I’ve created for it. Some great community members have stepped up and filled my place at times, while I have at least tried to stay active on the mailing lists and in the IRC channels. I’ve still guided and cut the last couple releases, but I haven’t played a part in shaping the future of the project.
There are multiple competing visions charting new paths for the aging project, with conflicting goals and revision histories, and it really needs a stronger leader to take the reins and guide the project to its next milestones. I’m unfortunately not the person to fill this role, for many reasons. Maybe a few years ago it would have been better timing.
Lately, I’ve come to the realization that I can no longer bring myself to work with PHP for personal projects. I don’t like the syntax, I don’t like where the language is heading, I don’t like how much memory and CPU it requires to run on a web server, and I just spend the whole time wishing I was writing Python code instead.
This blog hasn’t run on PHP or a database for just over a year now, and with my MantisBT install being used mainly for projects I don’t have the time or will to work on, it just seems to be dead weight. Github can serve my needs well enough for the few remaining projects I work on, and without needing a complicated setup on my end. Turning off MantisBT means I no longer need MySQL, PHPMyAdmin, APC, or even mod_php at all. The remaining apps can easily be replaced with external services.
So basically, this is me announcing what I’ve already been practicing for many months now: I will no longer be a developer for Mantis Bug Tracker, but I will remain involved as a mentor for other core developers, or for those seeking some advice on my plugins or creating their own. I won’t be maintaining any of my plugins, but I will look at and accept pull requests until someone else wants to step up as maintainer. I will be removing MantisBT from my site, but will keep a database dump in case I ever need to reference it in the future.
This is not me withdrawing from open source; I have many other projects that I’ve been working on, most of which are written in Python or C++. I find them more enjoyable to deal with, and most importantly, they allow me to break out of the realm of writing web applications. IRC, as old as it is, has been my point of intrigue lately, and is at the core of my current “pet” project.
Regardless of language, you can still find me on Github, where all my toys are available for the public to point and laugh at. And as always, I will answer questions on Freenode as “amyreese”, or via email, although there may sometimes be a long delay before I can reply.
Thank you to everyone who’s contributed to MantisBT or its plugins, and thank you to everyone who helped me on the way to where I’m going.
This is Why I Write Open Source Software
Hey man,
Just wanted to say thanks for the ZNC Push Module you made. I’m using it with Notify My Android and it works great! This should be a standard module in ZNC imo. Stellar work my friend.
Best,
~Lucien
It makes me smile every time I hear from someone using my software, knowing that I can make an impact on peoples daily lives, no matter how small it may be. Thank you to everyone who has taken the time to thank me for my work.
EA BioWare
Last week, I received an offer from EA BioWare: they want me to join their San Francisco operations team as a Platform Systems Engineer! I still can’t believe that this is happening, but I’m going to be moving to California to work for a game studio. This is practically my dreams come true, and I’m excited and overwhelmed beyond my imagination.
I won’t be working on games directly, but I’ll be working in a devops role to automate and manage servers for games and internal projects. It’s a good fit with my experience in web applications, system administration, and tool development. It also can be a potential stepping stone to a game development position later on.
The next two months are likely to be hectic, as I move to temporary housing in California, and then find an apartment and move into it. Ongoing projects may have to take a back seat until I can get the free time again. But the weather and job will be worth it!
ZNC Push
Based around the core conditions and functionality from my original project,
ZNC Push is a module for ZNC that will send push notifications to multiple
services for any private message or channel highlight that matches a
configurable set of conditions, including the user’s /away status, time since
the last notification, number of clients connected to ZNC, and more. Currently
supported push services include Boxcar, NMA, Notifo, Pushover,
Prowl, and Supertoasty.
The module is released under the MIT license, and the source code and full documentation can be found on the project’s Github repository page.
IRC, My Way
This is a post I’ve been meaning to write for a long time. I have a rather complicated setup involving multiple layers, but the end result is amazing. I maintain a 24/7 presence on the internet — on multiple IRC servers and instant messaging services — and I can send and receive messages from any computer or device I happen to be using at the time.
From any SSH client, I can seamlessly pick up my IRC session where I last left it, regardless of where I started that session. Similarly, I can connect with my phone’s IRC client, get a short backlog of recent conversations, or answer pending private messages. When I’m not already engaged in a conversation, I get near-instant notification on my phone and desktop, allowing me to respond at my leisure and from any location. I never miss a private message because I was connected from the wrong place, other users always see a single nick, and I get a central, searchable history of every channel and private message.
With this sort of setup, I gain a lot of freedom — to deal with conversations on my terms — and convenience. It’s served me well for a couple years, and I’ve enjoyed IRC much more since putting it all together. For each layer, I’ll detail the tasks it covers, the software I’ve chosen, and give a copy of any configuration files or options needed to replicate my environment.
Air Force Museum Photos
Yesterday, my wife and I visited the National Museum of the United States Air Force at Wright-Patterson AFB in Dayton, Ohio. We walked through the three main hangars, mostly in chronological order. I snapped a lot of pictures along the way with my Nexus S; I picked out the blurry duplicates where possible, and captioned the photos as best I could. They actually turned out better than expected, considering the low light levels and how unsteady my arms got.
I didn’t get to take pictures of the XB-70 like I wanted to though; it was in their Research and Development hangar, which requires an ID check and bus ride to visit. Hopefully we’ll get to return soon and rectify that.
The full gallery is on Picasa, and contains 130 photos.




Spotify Gnome Integration
Spotify-Gnome is a program that provides Gnome media key support for the Spotify Linux client. It supports the play/pause, stop, next, and previous signals, and is compatible with both Gnome 2 and Gnome 3.
The Spotify client supports DBus for controlling the player, using the MPRIS Specification, but does not listen for basic media key signals provided by Gnome. This program acts as a “wrapper” around Spotify to translate media key signals from Gnome and send them to the Spotify client.
The program is released under the MIT license, and the source code and documentation can be found on the project’s Github repository page.
Many thanks to Mike Houston at kothar.net and Fran Dieguez at Mabishu for their blog postings that pointed me in the right directions to get this implemented.